
Generative AI as a tool
 There is a lot of fear around Generative AI and a lot of concerns about the ethics of how it is trained and how people use it. However, I consider it an incredible tool. In this devlog, I will give some of my thoughts around the controversies and document how I use Stable Diffusion to build the graphics of some of my games.
There is a lot of fear around Generative AI and a lot of concerns about the ethics of how it is trained and how people use it. However, I consider it an incredible tool. In this devlog, I will give some of my thoughts around the controversies and document how I use Stable Diffusion to build the graphics of some of my games.
I can’t draw. Looking at references, I struggle to draw what I see. I cannot really draw from imagination. I think I have aphantasia. Although I have not been evaluated, I don’t really see things when I imagine them the way it seems others do. I describe my experience to people of imagining something similar to my feeling of reading a description of something in a book. I am imagining the description of the image. Maybe I am just wrong here, and I am no different from anyone else, but it is not important. What is important is that I am not very skilled at drawing.
As an indie game developer, I need art. My options are basically:
- Make it myself
- Commission someone or find someone willing to work for free
- Buy stock images, or use CC0 or CC-BY artwork
Using pre-existing images is great for some things, but for something like a translite for my game, that doesn’t work. Commissioning work is something I would like to do at some point. But services like Fiverr have their own issues, and it can be hard to communicate what I am looking for. If I had a network of artist friends, maybe I could work more closely with one of them, but this is hard. Also, my budget for a game like Blood Bank Billiards is not large. It would be difficult for me to pay what an artist would deserve.
So that leaves me to do it myself. But as I said, I am not a good artist. Enter generative AI. Am I taking work away from an artist? Maybe, but I cannot afford to pay for one. So I will let you decide if I am evil after reading my post.
The Making of the Blood Bank Billiards Backglass
Inspiration
My vision for the backglass was for it to be something like Eight Ball Champ, Eight Ball Deluxe or Cue Ball Wizard. I wanted a vampire standing on the other side of a pool table as my opponent. I imagined the vampire wearing a vest like Eight Ball Champ.
I started with the translite before the in game environment was added. So I was imagining the blood bank as an underground vampire speakeasy bar that serves blood and has pool tables. The art style I wanted was a pen and ink, mostly grayscale style. I wanted it to fit with the Edward Gorey inspired look of Drained, but I wanted it to be uniquely its own style.
Exploration
These images were created using Stable Diffusion XL. I will get more into why I choose this model as I discuss generative AI. But the short version is
- I think Stability AI makes reasonably ethical choices when building their models (especially 2.0 and later)
- Their licensing terms are very open for this type of use
- Inference can be done entirely on my local machine
- I like the results
I started by exploring the prompt space and narrowing into the layout and style I had in mind. Once I had a good starting point, I used img2img to explore and refine the idea. Here is one of the early grids as I was refining the image.
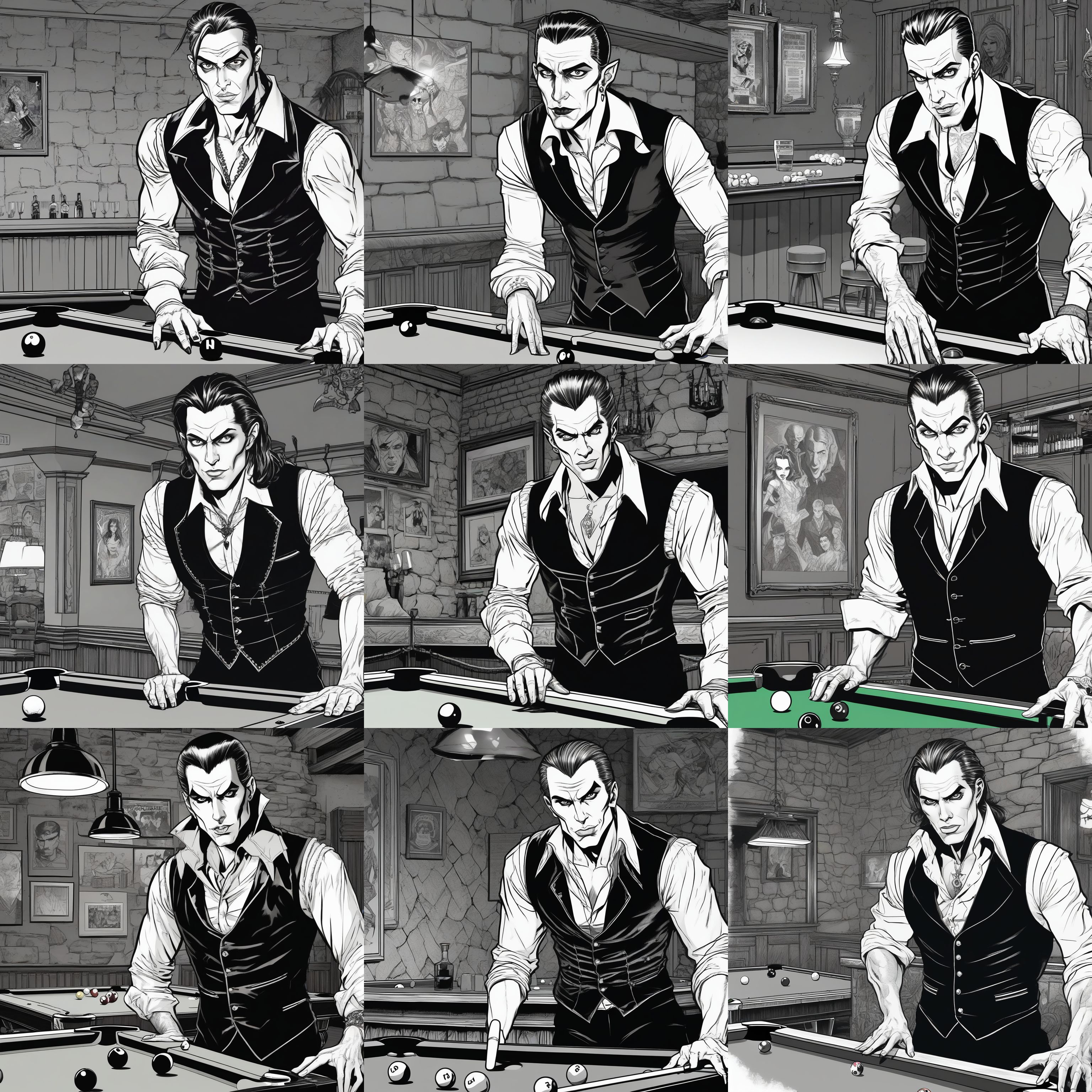
The prompt was:
ink drawing of a vampire standing behind a pool table in a graphic novel cover art, stone walls in the background, gothic, black and white, basement, dressed in a vest, looking at the camera
Negative prompt:
window, doors, noise, dull, washed out, low contrast, blurry, deep-fried, hazy, malformed, warped, deformed
You can see the start of what ended up being the final image starting to come through. Much random trial and error, and infinite number of monkeys eventually I was pretty happy with this image as a starting point.

I went through a bunch more refinement, that is not super interesting, but eventually was somewhat happy. There is a lot wrong with this image. The hands are bad. The chest makes no sense. The background makes no sense. There are anatomy issues. This would not be usable as a final image, but it is a great starting point for me.
Making the image 1080p
Using SDXL, I was creating a 1024x1024 image. But my backglass is 1920x1080, so I needed to outfill my image. I again let the AI do this. It was a bunch of work to bring this together, but came out with this starting point image.

In the Beta, I used this backglass for the first while, to allow myself to understand what I wanted for the final backglass.

This is where the AI ends and I take over.
Drawing the image
The Character
This is obviously not really ready to be a backglass. I wanted the image to be a vector image that I could ultimately print translites with if I wanted. I needed to fix everything. And I wanted the image to be hand drawn by me, even if it is not my original concept. Every line was drawn by me in inkscape, mostly on my Huion pen display.
Some of the refinement I just couldn’t visualize on a computer. So a few things I needed to print up and draw with a pencil (and get Chantelle James to help me). Here are those 2 images. (ignore the fact that they are really greasy for some reason, gross)
Something was just off about the nose. I could not see it. The shading was wrong. It was making the shape wrong. This is the refinement.

In the AI art, the chest and shirt blended into one. The character was wearing an Ankh on a chain, but again it was not right. This defined the buttons on the shirt, defined the collar, and refined the chest. I also needed to correct the light source and shadow inconsistencies. Ultimately it was still wrong, I was missing the collar bone, which I added later.

There was a lot of refining of the hands, and general cleanup, which led to this character image. I don’t think just showing this image captures the amount of work I put into transforming this.

Adding the scenery
The next step was to align the image of the character with the view of the actual scene in the game (“Bar” by Edward Joseph is licensed under Creative Commons Attribution CC BY 4.0.) This is a rendering from Unity with the textures replaced with an outline filter.

Then I started to texture the environment. Here I am adding detail of wood grain to the flooring.
Next I focused on drawing all the bricks onto the wall. I used a grid of perspective reference lines and then drew all these edges by hand. I ended up using a “sand” texture to fill the bricks because I felt I was not up to trying to do it manually.

Putting this all, here is the initial drawn backglass. There was a bunch more texturing of the rest of the environment as well as adding all the pinball overlay and creating the virtual backlit elements for things like ball counts, player up, over the top, tilt, shoot again and other pinball things. There are 2176 paths in this image and just over 4000 objects (although not all of this is part of the end image). I include this to give a rough idea of the detail of the work. I am probably very inefficient in how I did this.

My Thoughts on Generative AI
This is not intended to be a comprehensive discussion of the concerns around Generative AI, but just some of my thoughts. Maybe this devlog will change your mind of using it as a tool for asset creation, or maybe you will hate what I have done and never want to play any of my games. But I want to put it out in the open.
Concerns around training data, consent and copying
All versions of Stable Diffusion are trained on a subset of LAION-5B as well as aesthetics models and clip models. But this is essentially five billion images with captions on the open internet. They filter out parts of the training set for quality, removing NSFW data, and in the model SD2.0 and later they implemented some degree of opt-out for artists that had concerns around SD1.0. For SD3.0 the opt-out removed about 80 million images for the dataset. In contrast to some other companies that hold their training dataset and process secret and proprietary, Stability is very open about everything. Other companies have expressed some pretty troubling statements about their training philosophy. The license also has an acceptable use policy, which forbids using the technology for various problematic use cases.
The images are images that are publicly viewable on the internet. There is a bit of an issue also with humans stealing other people’s art and sharing it in other places. Ultimately the provenance of this art and who owns the copyright is lost. The initial training is done on 256x256 px images and then they refine larger images. This is one of the things I find interesting, because at 256px, the art they are training on is not very representative of most art. Here is the first image at 256px. This is enough to learn about composition and rough concepts, but certainly not fine detail. In reality, the model trains on a 64x64 image after being compressed by the VAE (although in a different space that we cannot visualize).

I like to think about this issue by thinking about what standard we hold human artists to. Every human artist is looking at reference images of other artists’ works over the years as they learn. Many will copy or mimic images or styles in learning and developing their own styles. Obviously, the computer is able to do this over a few months for billions of images and maybe the scale at which they can do this makes it different.
One of the things I like about using AI to generate references (even though I go further than that and trace) is that it is more removed from the references. If an artist is looking at Eight Ball Champ and Eight Ball Deluxe backglass as inspiration, I feel there is a good chance of mimicking that work more. The generative AI may have trained on those backglasses, but there was nothing specifically referencing them in anything I did. There is a bit more isolation between the copyrighted inspiration than in the human case.
But ultimately, what the model learns is a combination of a lot of artists, and it is capable of producing copies of art from its training set. I don’t know if the character in my game is a copy of someone else’s art or not.
It is also worth pointing out that there are many fine tuned models (and LoRa) that are derivatives of Stable Diffusion on the internet. Some of these models produce amazing results. However, these models tend to be very bad in terms of respecting copyright. Many are explicitly trained on copyrighted materials to copy a style, such are Blu-ray captures. Without knowing first hand what the training data was, I would avoid anything but the base models.
Concerns around taking work away from human artists
Did I take work away from a human artist? Maybe. I don’t think I could have afforded to pay someone. My experience with Fiverr is that I have my doubts that some of the artists are not just stealing art from internet searches anyway. I think ultimately this game would not exist if I needed to hire an artist.
Concerns around copyright and ownership
Stable Diffusion XL has a permissive license and it is allowed to use for commercial applications (not legal advice, read the license yourself). There continue to be a lot of open questions about the copyright of derivative work. I have no idea what the copyright status of this backglass is. The generative AI output cannot be copyrighted right now. So that work is basically public domain. Arguably the entire work is also a derivative of Bar, so maybe Edward Joseph owns the copyright to my backglass. Or maybe I did enough work (I know I spent a lot of time) that I own the copyright. I am honestly not sure. But I feel like I have done my best to be upfront and honest and satisfy the license terms of everything I used in my game.
Generative AI in other games
I am not going to go into as much detail on the process in my other games, but here is a sampling of some of my other uses of generative AI.
Time Flies Like An Arrow
Here are some behind the scenes looks into some of the AI inspiration images for the characters in Time Flies Like An Arrow, my Playdate game. Each character is distilled down into a 1-bit 42x42 pixel full body sprite and a 64x64 pixel portrait. The first image shows a bunch of the exploration I did on generating some of the early concepts for the Chief (and a few other things). Martin Rex is a time traveling dog and Rufio works for a record label and signs acts through time.



Bird Watcher
In Bird Watcher, I used generative AI to build a billboard advertising something related to the environment and bird of the module. Here are a few of the signs.


